Midterm Checkpoint
Introduction/Background
The intersection of music and machine learning has been a vibrant area of research, with significant breakthroughs in both music classification and generation. In 2002, Tzanetakis proposed three feature sets specifically for genre classification [1], which laid the groundwork for following studies. Li further refined feature extraction by proposing Daubechies Wavelet Coefficient Histograms [2]. Method-wise, Lerch [3] proposed a hierarchical system, granting expansion capabilities and flexibility. Model-wise, both deep-learning and traditional machine-learning approaches are applied and examined [4].
Our dataset comprises 10 genres, each with 100 audio files of 30 seconds in length, accompanied by image visual representations for each file. It also includes two CSV files: one details mean and variance of multiple features extracted from each 30-second song, and the other provides similar data, but the songs were split before into 3 seconds audio files. For our project, we will be testing with the 30 seconds data, but training with two approaches, the 30 seconds ones (current) and the 3 seconds ones (next step).
We are mostly interested in tempo, root mean square (RMS), spectral features such as centroid, bandwidth, and rolloff capture different aspects of the frequency content, zero crossing rate measures the noisiness, MFCCs related to the timbral texture of the sound, harmony, chroma that captures the intensity of the 12 different pitch classes, etc. These are the more significant features in DL and traditional ML learning [4].
Link to the GTZAN dataset.
Problem Definition
The primary issue addressed is the use of machine learning techniques to classify music into genres. The possibility of improving the existing music recommendation algorithms serves as its driving force. We can promote a deeper understanding of musical structures and music creation and give listeners a more engaging and personalized experience by appropriately classifying different genres of music. The issue is justified with economic concerns. When consumers are constantly presented with irrelevant suggestions, poor recommendation algorithms not only make the user experience worse but may also cause streaming platforms to incur financial losses. The project’s goal is to strengthen the bond between listeners and music, which will benefit streaming services’ bottom line as well as their audience’s general contentment.
Strategy 1 (Initial Approach)
Methods
Exploratory data analysis (visualization of a MFCC & Chroma plot):
 In the data preprocessing stage, we generate 12-channel Mel-Frequency Cepstral Coefficients (MFCC) and Chroma graphs along with their first and second derivatives as representations of the raw audio signals. MFCC and Chroma features are widely used in music genre classification tasks as they capture essential information about the audio’s spectral and harmonic content. The data preprocessing pipeline is illustrated in the following workflow:
In the data preprocessing stage, we generate 12-channel Mel-Frequency Cepstral Coefficients (MFCC) and Chroma graphs along with their first and second derivatives as representations of the raw audio signals. MFCC and Chroma features are widely used in music genre classification tasks as they capture essential information about the audio’s spectral and harmonic content. The data preprocessing pipeline is illustrated in the following workflow:
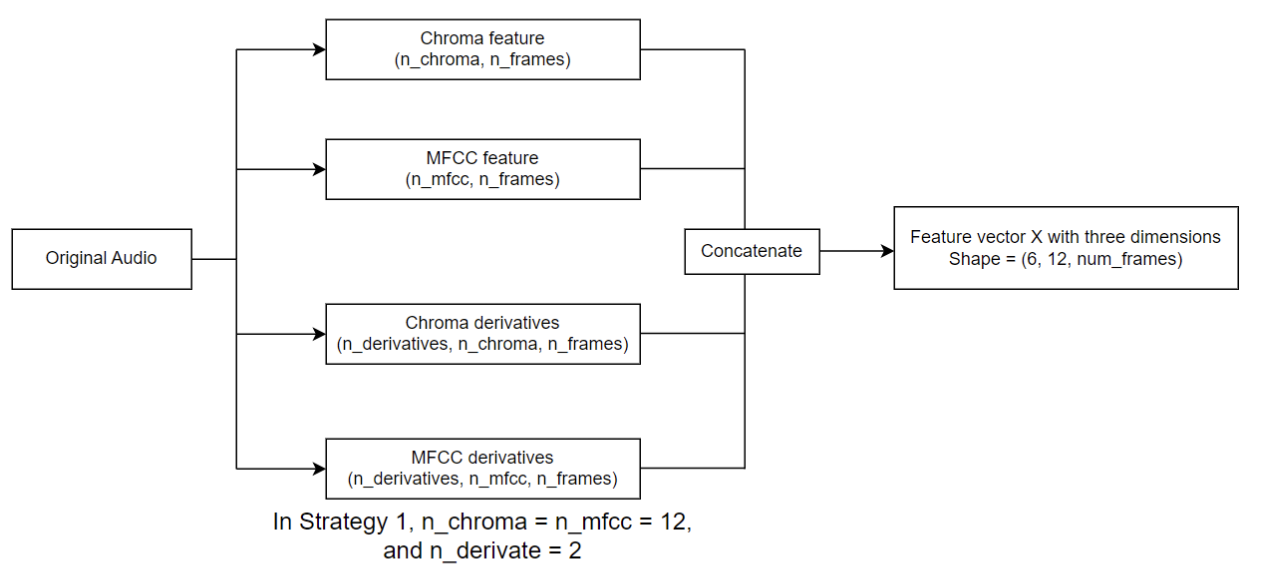 The preprocessing pipeline ensures that the raw audio signals are transformed into a suitable format for further analysis and modeling.
After obtaining a vectorized representation of each audio signal, we proceed to fit the dataset using various machine learning models. The workflow for model fitting is depicted below (results are based on a 5-fold cross validation):
The preprocessing pipeline ensures that the raw audio signals are transformed into a suitable format for further analysis and modeling.
After obtaining a vectorized representation of each audio signal, we proceed to fit the dataset using various machine learning models. The workflow for model fitting is depicted below (results are based on a 5-fold cross validation):
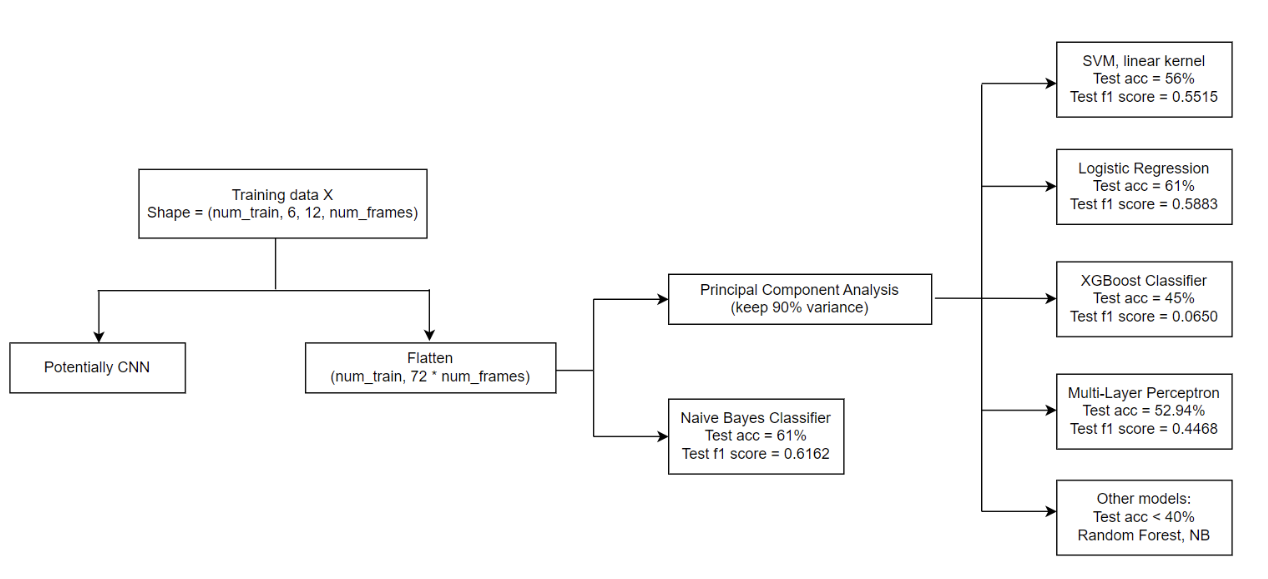 To reduce the dimensionality of the preprocessed data and improve model performance, we apply Principal Component Analysis (PCA) before fitting most of the models. By reducing the dimensionality, we aim to mitigate the curse of dimensionality and enhance the efficiency of the models.
To reduce the dimensionality of the preprocessed data and improve model performance, we apply Principal Component Analysis (PCA) before fitting most of the models. By reducing the dimensionality, we aim to mitigate the curse of dimensionality and enhance the efficiency of the models.
Results and Discussion
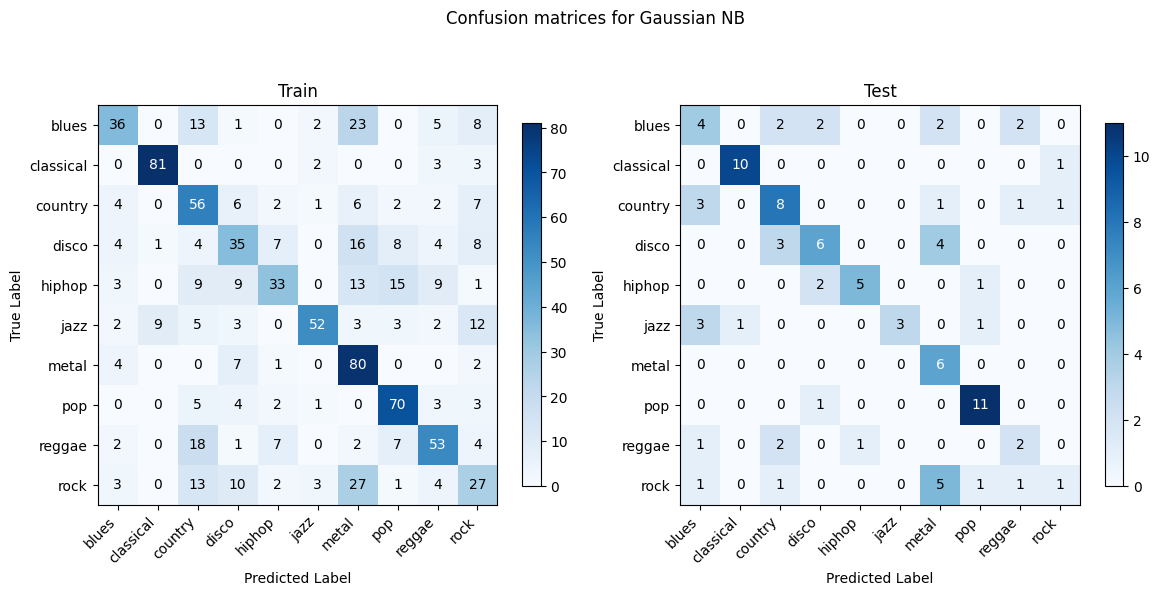
The best-performing model is Gaussian Naive Bayes, with a confusion matrix as follows:
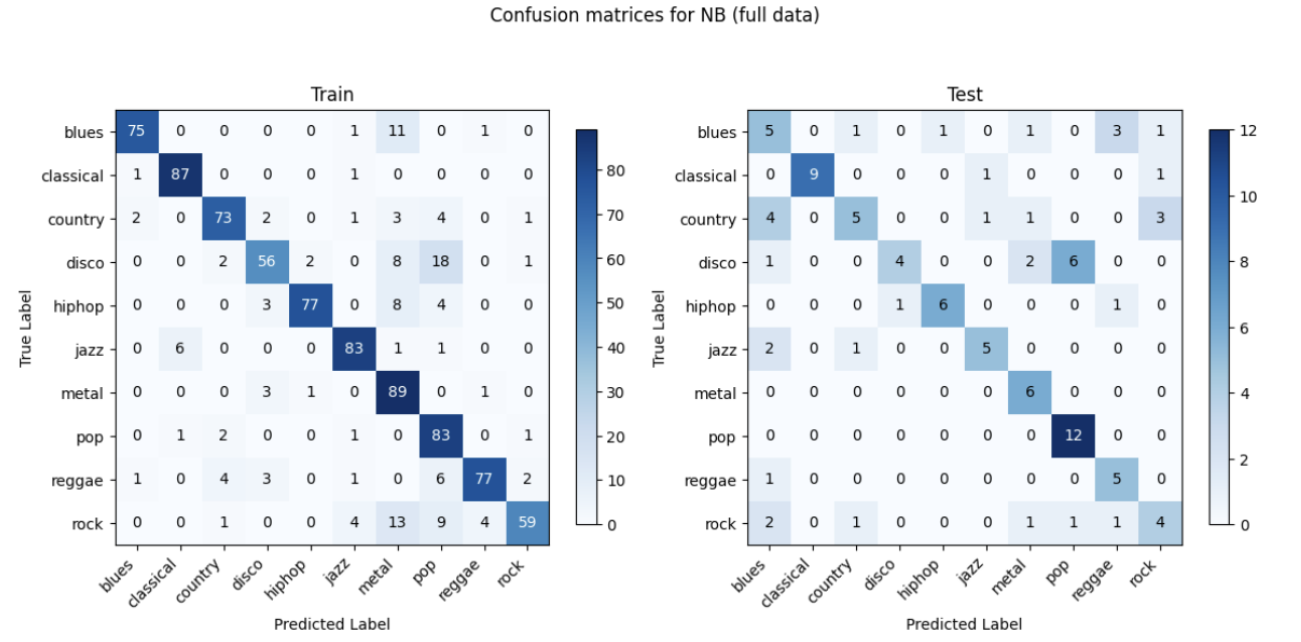
The initial approach of using the entire MFCC and Chroma graphs as features for music genre classification unfortunately yielded suboptimal results. Despite several attempts at hyperparameter tuning, the performance of the models remained around 60%. This suggests that there are limitations to this strategy that hinder further improvement.
After group discussions, we hypothesize that the main reason for the subpar performance lies in the high dimensionality introduced by considering the entire MFCC and Chroma graphs. Even after applying dimensionality reduction techniques like PCA, the number of features remains substantial (around 600 features for each audio), leading to the curse of dimensionality. The models struggle to effectively learn and generalize from such a large feature space, resulting in limited classification accuracy.
To address this issue, we propose a solution is to reduce the number of features by focusing on key characteristics of the MFCC and Chroma graphs instead of using the entire graphs. By extracting relevant statistical measures, such as means, variances, or other domain-specific metrics, we can create a more compact and informative representation of the audio signals. This approach allows us to incorporate additional graphs and features, such as spectrograms, tempo graphs, and root mean square (RMS) values, without excessively increasing the dimensionality.
By carefully selecting and engineering features that capture the essential information from the audio signals, we can potentially improve the performance of the music genre classification models. This refined approach strikes a balance between representational power and model complexity, enabling the models to better learn and generalize from the data, and there comes a natural transition to our second strategy.
Strategy 2
Methods
For data preprocessing, we referenced the IEEE paper [4] and generated 77 features (eg. tempo, rms_mean, rms_var, etc.) for each 30-second audio. We started by importing necessary libraries like librosa for audio processing. Then extracting the meaningful features to convert raw audio signals into a structured form so that we can see the underlying patterns that can differentiate audio samples. Then, we took steps to organize the extracted features into a NumPy array, along with corresponding labels (supervised learning setup). The categorical labels are converted into numerical format and the dataset is assembled into a pandas DataFrame so that it is easier to apply further steps.
The 77 features we used are: Mean and variance of root-mean-square of frames, spectral centroid, spectral bandwidth, spectral rolloff, zero crossing rate, harmony, 20 MFCC and 12 Chromas, and tempo as a scalar.
Traditional machine learning models, such as SVM and logistic regression, have been widely used in music genre classifications. Therefore, we decided to start with them. Unlike deep learning models, traditional ML models require hand-crafted features and careful feature engineering for optimal performance [5]. This approach not only leverages the proven strengths of traditional algorithms but also underscores the significance of our custom feature extraction method. We mainly focused on logistic regression, SVM, OVO SVM, random forest classification, Gaussian naive bayes, XGBoost, which are all implemented as supervised learning.
Results and Discussion
Results
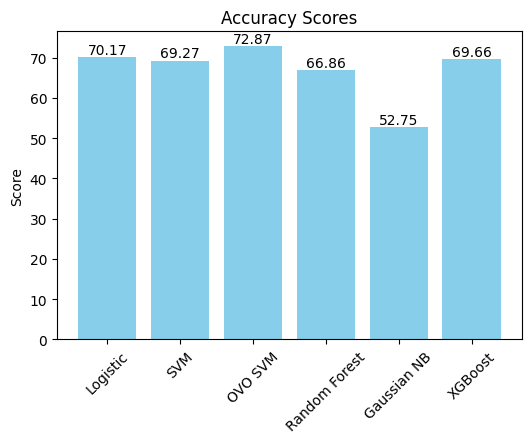
The second strategy, which involves generating 77 custom features for each 30-second audio segment and applying traditional machine learning models, has shown significant improvement compared to the first approach. The results obtained using this method have reached an accuracy of 73% under 5-fold cross-validation, demonstrating the effectiveness of feature engineering and the selected machine learning algorithms.
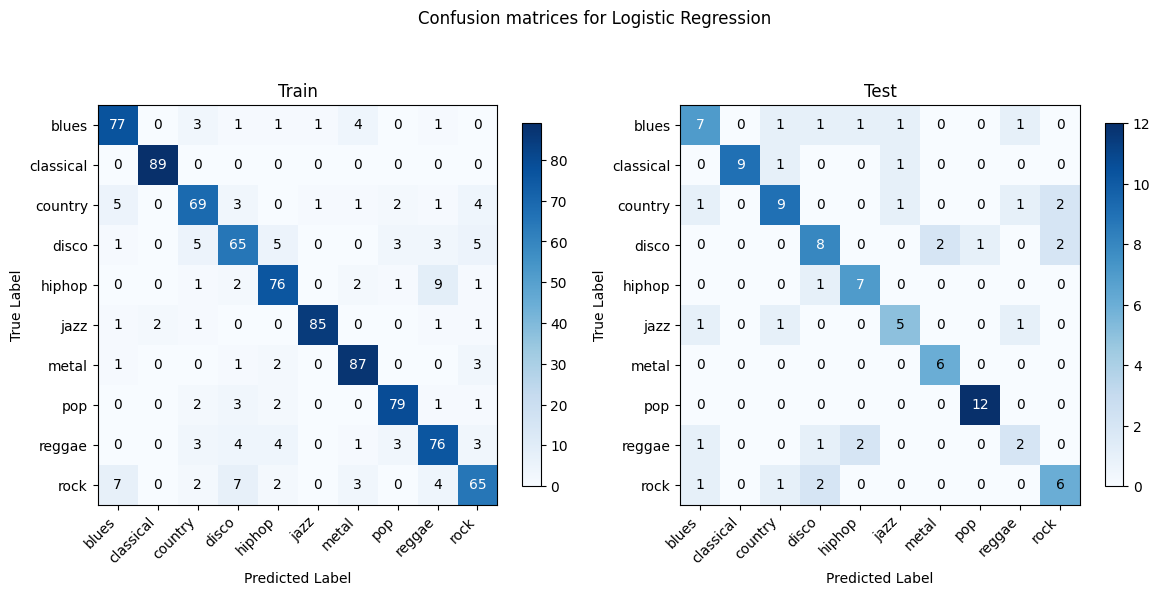
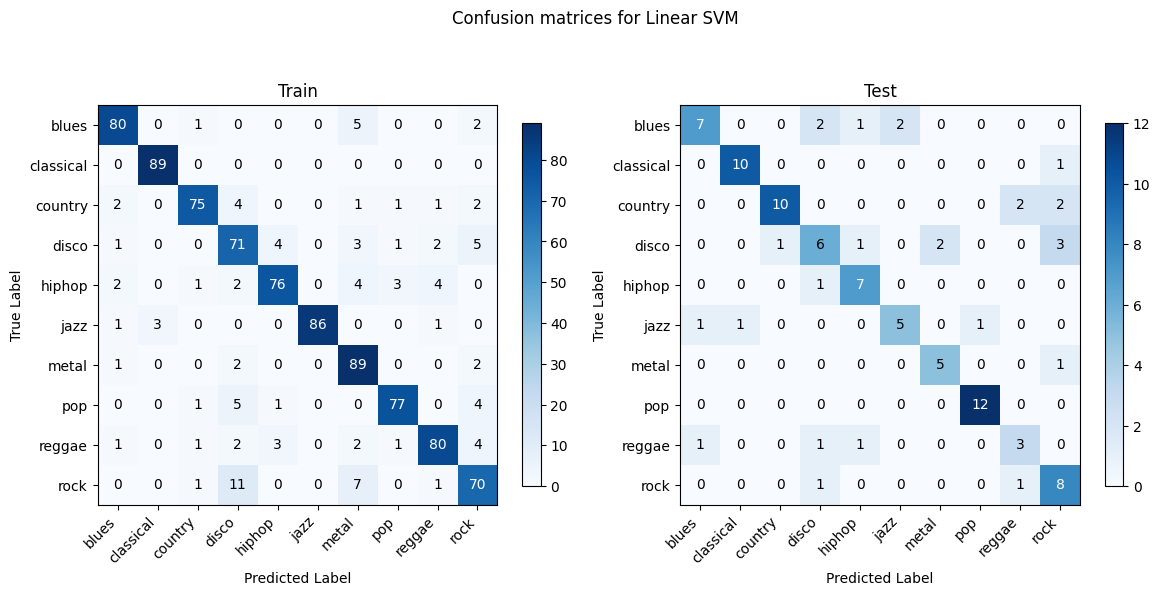
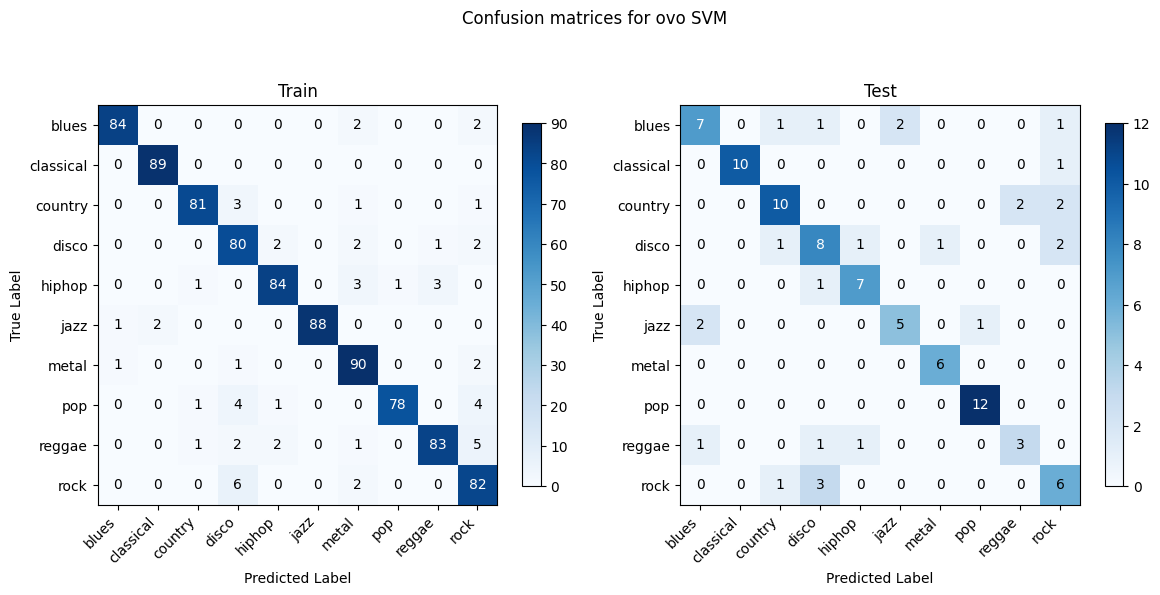
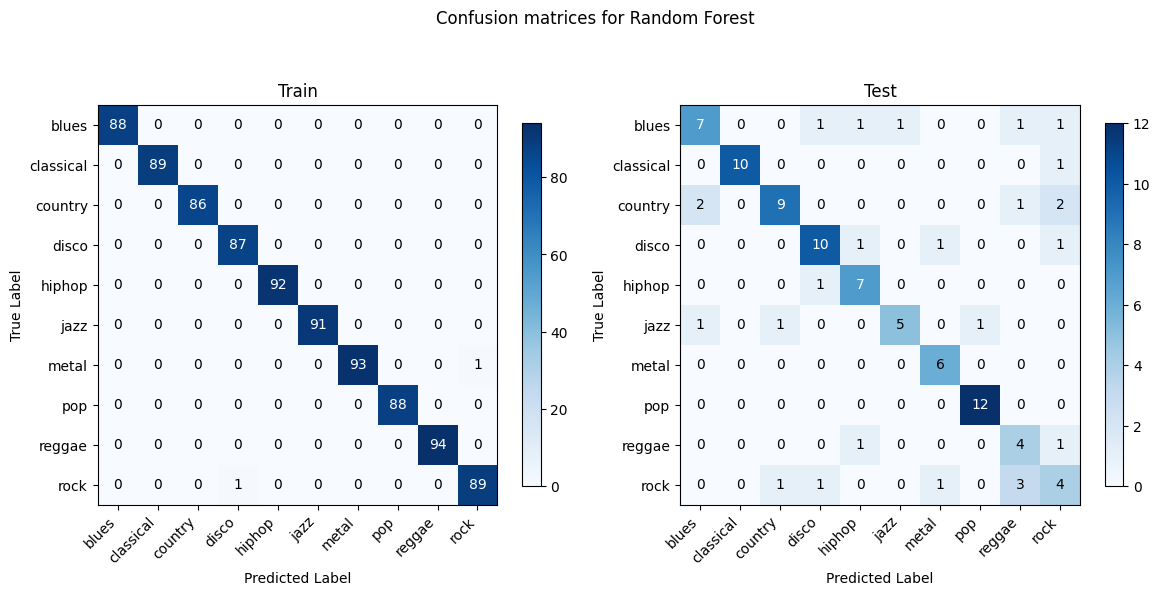
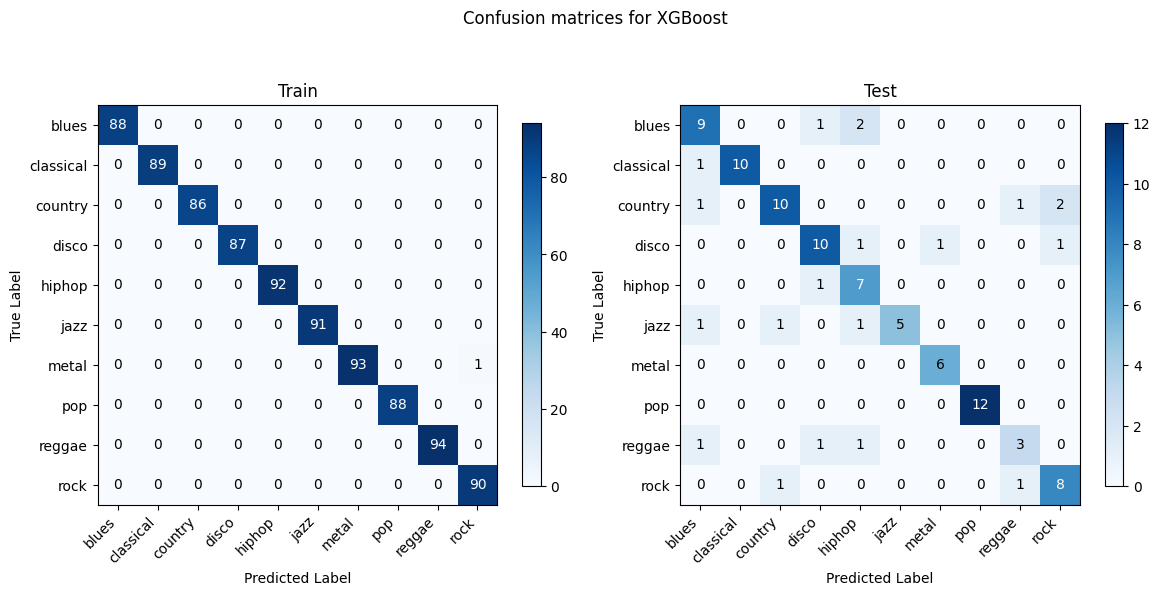
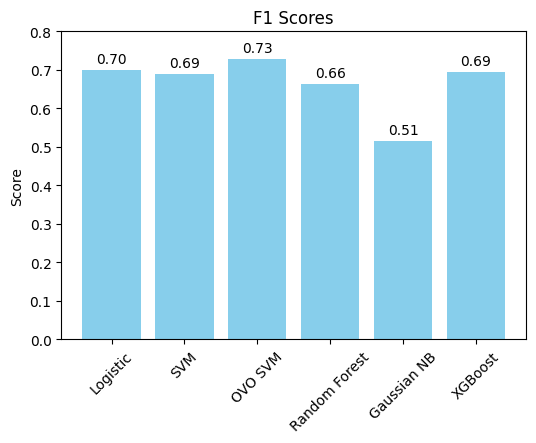
Random Forest and XGBoost show the most consistency between training and testing as they are better at generalizing and less prone to overfitting. Linear SVM and OVO SVM have decent generalization with a lower discrepancy between training and testing performances compared to Gaussian NB. Gaussian NB and Logistic Regression struggle with certain genres such as blues, country, and rock. Gaussian NB shows signs of overfitting.
OVO SVM holds the highest test accuracy (72.87%). Gaussian NB presents the lowest accuracy (52.75%).
OVO SVM holds the highest F1 score (0.73), indicating a strong balance between precision and recall, whereas Gaussian NB has the lowest F1 (0.51), which is consistent with the confusion matrix where it faces challenges in several genres and overfitting.
OVO SVM in this case presents the most well-performing result. This might be due to several factors. The audio data, when transformed into features like MFCCs, Chroma, etc., usually result in a high-dimensional space. Each dimension represents a particular characteristic of the sound. The SVM with RBF kernel excels in such environments as it does not get overwhelmed by the number of features and instead uses them to construct a hyperplane that can separate the genres with maximum margin. The RBF kernel is particularly adept at dealing with non-linearity. SVM is based on the concept of the distance between the separating hyperplane and the nearest points from both classes. Maximizing the margin tends to increase the model’s robustness and its ability to generalize. The SVM’s regularization parameter C also plays a pivotal role in controlling the trade-off between achieving a large margin and minimizing the classification error. This can prevent the model from overfitting.
We also did hyperparameter tuning on all six traditional machine learning models, but the test accuracy increased by a maximum of 1% for logistic regression and random forest, whereas other models remain about the same, so we figured to use default values instead.
Problem
It is important to acknowledge that manual feature selection can be a challenging and time-consuming process. It requires domain expertise and extensive experimentation to identify the most informative and discriminative features for music genre classification. Despite the improvement in accuracy, the current result of 73% still falls short of our desired goal of achieving a satisfactory model with a test accuracy exceeding 80%.
Potential Solution (Next Step)
To further enhance the performance of our music genre classification system, we propose some potential solutions. Firstly, we can expand the training dataset by splitting each 30-second audio segment into ten 3-second segments. This approach would effectively increase the size of the training set by a factor of ten, providing more diverse and representative examples for the models to learn from. By exposing the models to a larger variety of audio snippets, we aim to improve their ability to generalize and capture the nuances of different music genres.
For each 30-second audio $a_i$, we do the following preprocessing:
-
Generate $n$ equal-length subsamples $a_{i0}, \dots a_{in}$ of $a_i$
-
Generate $m$ (in our current implementation $m=77$) features for each subsample $a_{ij}$ to get vector representation $x_{ij} \in \mathbb{R}^m$.
-
Train a machine-learning model that takes $x_{ij}$ as input and outputs a $(10,)$-shape vector $w_{ij}$, with entry $i$ represents the probability (or confidence) that the three-second sample $a_{ij}$ belongs to class $i$.
-
Classify sample $a_i$ based on the mode of all $w_{ij}$ whose value is greater than a pre-set threshold.
Secondly, we can explore the application of deep learning models, such as Multilayer Perceptron (MLP), for more intelligent feature selection. Deep learning models have the capability to automatically learn and extract relevant features from raw data, reducing the reliance on manual feature engineering. By leveraging the power of deep neural networks, we can potentially discover more complex and discriminative patterns in the audio signals, leading to improved classification accuracy.
Additionally, we could classify the spectrograms using pretrained CNN by generating spectrograms on the raw audios and fine-tune a reliable, well-performing CNN architecture such as VGG / ResNet.
References
[1]: Tzanetakis, G. and Cook, P. (2002) ‘Musical genre classification of Audio Signals’, IEEE Transactions on Speech and Audio Processing, 10(5), pp. 293-302. doi:10.1109/tsa.2002.800560.
[2]: Li, T., Ogihara, M., & Li, Q. (2003, July). A comparative study on content-based music genre classification. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval (pp. 282-289).
[3]: Burred, J. J., & Lerch, A. (2003, September). A hierarchical approach to automatic musical genre classification. In Proceedings of the 6th international conference on digital audio effects (pp. 8-11).
[4]: Ndou, N., Ajoodha, R., & Jadhav, A. (2021, April). Music genre classification: A review of deep-learning and traditional machine-learning approaches. In 2021 IEEE International IOT, Electronics and Mechatronics Conference (pp. 1-6). IEEE
[5] Bahuleyan, H. (2018). Music Genre Classification using Machine Learning Techniques. arXiv:1804.01149v1
Contribution Table
Gantt Chart
Here is the Gantt Chart.